Functional Programming and Django QuerySets
LA Django Meetup
July 5th, 2016
tiny.cc/jtaqs4
LA Django Meetup
July 5th, 2016
tiny.cc/jtaqs4
Note
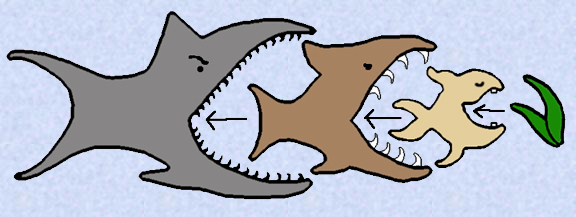
iterator/generator = "stream"
Functional Programming: programming with composition
QuerySet is a stream
Note
<https://en.wikipedia.org/wiki/Function_composition_%28computer_science%29 >`
combine simple functions to build more complicated ones

An iterator is a stream of data—sort of a restricted, compact list or cursor.
>>> list([1,2])
[1, 2]
>>> iter([1,2])
<listiterator object at 0x7f429d83c750>
Note
mdash: http://docutils.sourceforge.net/FAQ.html
iterators have a item and next and that's it - Preferred, because they take almost no space
iterate across a stream of strings
>>> f = open('recipe.ini')
>>> for line in f:
print line
# very tasty
[Old Fashioned]
1:1.5 oz whiskey
2:1 tsp water
3:0.5 tsp sugar
4:2 dash bitters
Note
you already use iterators
Ex: Database iterator
for line in open('ing.txt'):
print line
for num in iter([2,4,6,8]):
print num
for num in [2,4,6,8]:
print num
for name in glob.iglob('*.txt'):
print name
>>> f = open('ing.txt')
>>> f.next()
'# Old Fashioned\n'
>>> f.next()
'1.5 oz whiskey\n'
>>> f = open('/dev/null')
>>> f.next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>> iter([]).next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
no slicing
>>> f = open('ing.txt')
>>> f[0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'file' object has no attribute '__getitem__'
no length
>>> f = open('ing.txt')
>>> len(f)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: object of type 'file' has no len()
| feature | list | iterator |
|---|---|---|
| overall | eager | lazy |
| memory | high | low |
| len(x) | yes | no |
| slice | x[:3] | islice(x, 3) |
| addition | x + y | chain(x, y) |
| has items | if x | no |
| easy debug | yes | no |
Note: Python 2/3 are quite different
Note
List are "eager" -- know everything about them all the time
Million item list can be rough, because they hold all million - have to deal with all items
Million item iter is no biggie, can proc a few
enumerate(iter)sorted(iter)range(stop)dict.iteritems()very important:
filter(func/None, iter)map(func, *iterables)and itertools, and fileinput
Note
tradeoff readability vs conciseness

- Modularity
- Composability!
- Ease of debugging and testing
- Parallelization
- Buzzwordy!
functions that operate on functions
>>> def is_odd(num):
return num % 2
>>> filter(is_odd, [1, 2, 3])
[1, 3]
list of instructions
can modify caller's state
object has state and functions to query/modify state
specialize by subclassing
procedural: list of instructions
def upfile(inpath, outpath):
with open(outpath, 'w') as outf:
for line in open(inpath):
outf.write( line.upper() )
upfile('ing.txt', '/dev/stdout')
Note
Note
[Many] Languages are procedural: programs are lists of instructions that tell the computer what to do with the program’s input.
object oriented: Object has state and specific functions to query/modify state. Easy to specialize by subclassing.
class RWFile(list):
def __init__(self, inpath):
super(Upcase, self).__init__(open(path))
def transform(self, line):
return line
def writelines(self, outpath):
with open(outpath, 'w') as outf:
for line in self:
outf.write( self.transform(line) )
class UpFile(RWFile):
def transform(self, line):
return line.upper()
UpFile('recipe.ini').writelines('/dev/stdout')
Note
Object-oriented programs manipulate collections of objects. Objects have internal state and support methods that query or modify this internal state in some way. Smalltalk and Java are object-oriented languages. C++ and Python are languages that support object-oriented programming, but don’t force the use of object-oriented features. ["Object obsessive"]
functions operate on streams of objects
combine simple functions => complicated
preferably without internal state
using a generator expression
open('out.txt', 'w').writelines(
line.upper() for line in open('in.txt')
)
Note
seed, then transforms recombine elements, vs specialize
specialize with named function and map
def upcase(line):
return line.upper()
open('out.txt', 'w').writelines(
map(upcase, open('in.txt'))
)
map(func, iter) -- transform items using a function
def square(num):
return num ** 2
>>> map(square, [1,2,3])
[1, 4, 9]
Note
function applies a passed-in function to each item in an iterable object and returns a list containing all the function call results.
filter(func, iter) -- provide items matching a function
def is_odd(num):
return num % 2
>>> filter(is_odd, [1, 2, 3])
[1, 3]
Note
The filter filters out items based on a test function which is a filter and apply functions to pairs of item and running result which is reduce.
Example: Windows INI-file parser; aka ConfigParser
# 1. stream of lines
import fileinput
lines = fileinput.input()
print ''.join( lines )
# very tasty
[Old Fashioned]
1:1.5 oz whiskey
2:1 tsp water
3:0.5 tsp sugar
4:2 dash bitters
# 2. stream of valid lines
import fileinput
from itertools import *
def has_comment(line):
return line.startswith('#')
def has_keyvalue(line):
return ':' in line
lines = ifilterfalse( has_comment, fileinput.input() )
lines = ifilter( has_keyvalue, lines )
print ''.join( lines )
1:1.5 oz whiskey
2:1 tsp water
3:0.5 tsp sugar
4:2 dash bitters
# 3. stream of key-value match objects
import fileinput, re
from itertools import *
def has_comment(line):
return line.startswith('#')
def parse_keyvalue(line):
m = re.match(r'(\S+):(.+)', line)
if m:
return m.groups()
return None
matches = (parse_keyvalue(line) for line in fileinput.input())
keyvalues = ifilter(None, matches)
print '\n'.join( (str(kv) for kv in keyvalues) )
('1', '1.5 oz whiskey')
('2', '1 tsp water')
('3', '0.5 tsp sugar')
('4', '2 dash bitters')
# 4. dictionary
import fileinput, re
from itertools import *
def has_comment(line):
return line.startswith('#')
def parse_keyvalue(line):
m = re.match(r'(\S+):(.+)', line)
if m:
return m.groups()
return None
lines = ifilterfalse(has_comment, fileinput.input())
matches = (parse_keyvalue(line) for line in lines)
keyvalues = ifilter(None, matches)
confdict = dict(keyvalues)
print confdict
{'1': '1.5 oz whiskey', '3': '0.5 tsp sugar', '2': '1 tsp water', '4': '2 dash bitters'}
|
|
chain(iter*) gives elements of each stream in order Equivalent to + for lists.
>>> [1,2] + [3]
[1, 2, 3]
>>> from itertools import *
>>> chain(iter([1,2]), iter([3]))
<itertools.chain object at 0x7f429d848510>
>>> list(_)
[1, 2, 3]
Note
stream of objects with state lazy vs eager
islice(iter, num) -- return first few items
>>> list([1, 2, 3])[:2]
[1,2]
>>> iter([1, 2, 3])[:2]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'listiterator' object has no attribute '__getitem__'
>>> itertools.islice(iter([1, 2, 3]), 2)
<itertools.islice object at 0x7f429d7de9f0>
>>> list(_)
[1, 2]
>>> def stem(word):
... """ Stem word to primitive form """
... return word.lower().rstrip(",.!:;'-\"").lstrip("'\"")
>>> from toolz import compose, frequencies, partial
>>> from toolz.curried import map
>>> wordcount = compose(frequencies, map(stem), str.split)
>>> sentence = "This cat jumped over this other cat!"
>>> wordcount(sentence)
{'this': 2, 'cat': 2, 'jumped': 1, 'over': 1, 'other': 1}
represents a stream of rows from the database
Note
models.py
source: http://blog.etianen.com/blog/2013/06/08/django-querysets/
QuerySets are Django's way of getting and updating data
>>> from django.db import models
class Meeting(models.Model):
name = models.CharField(max_length=100)
meet_date = models.DateTimeField()
>>> m = Meeting.objects.get(id=12)
<Meeting: Meeting object>
>>> vars( Meeting.objects.get(id=12) )
{'meet_date': datetime.datetime(2016, 7, 5, 7, 0, tzinfo=<UTC>),
'_state': <django.db.models.base.ModelState object at 0x2bd1050>,
'id': 3, 'name': u'LA Django Monthly Meeting'}
>>> x = Meeting.objects.filter(name__icontains='go')
>>> for a in x: print a.name
LA Django Monthly Meeting
QuerySets can be shifty
>>> x = Meeting.objects.filter(name='java')
>>> x
[]
>>> type(x)
<class 'django.db.models.query.QuerySet'>
How can you tell if a list is empty or not?
- an iterator?
- a QuerySet?
Note
How can you tell if a list is empty or not?
>>> bool([])
False
>>> bool(['beer'])
True
Note
Lists are eager -- always know everything
Note
How can you tell if an iterator is empty or not?
>>> x=iter([1,2])
>>> bool(x)
True
>>> x=iter([])
>>> bool(x)
True
Note
Iterators are lazy -- don't know what they contain!
filter with QuerySet:
>>> from meetup.models import *
>>> Meeting.objects.filter(id=1)
[<Meeting: Meeting object>]
filter with list:
>>> filter(lambda d: d['id']==1, [{'id':1}, {'id':2}])
[{'id': 1}]
filter with iterator:
>>> list(ifilter(lambda d: d['id']==1, iter([{'id':1}, {'id':2}])))
[{'id': 1}]
>>> from meetup.models import *
>>> Meeting.objects.filter(id=1)
[<Meeting: Meeting object>]
>>> type(Meeting.objects.filter(id=1))
<class 'django.db.models.query.QuerySet'>
Note
similar to iter: dynamic/lazy; list(qs)
diff: stream of objs, same class qs[:3] <=> islice(it, 3) bool(iter) vs qs.empty()
>>> a=iter([])
>>> bool(a)
True
>>> a=[] ; bool(a)
False
qs.count()
laziness is explicit: prefetch_related
qs.values(); qs.values_list(); qs.values-list(flat=True)
>>> Meeting.objects.all()[0].id
1
>>> islice( Meeting.objects.all(), 1).next().id
1
>>> from itertools import *
>>> islice( Meeting.objects.all(), 1)
<itertools.islice object at 0x2bb9ec0>
>>> list(islice( Meeting.objects.all(), 1))
[<Meeting: Meeting object>]
How can you tell if a QuerySet is empty or not?
Use x.exists(), not bool(x) -- more efficient
Note
https://docs.djangoproject.com/en/1.9/ref/models/querysets/#exists
Both iterators and QuerySets are lazy
In functional programming, we have functions which operate on infinite-length streams.
With QuerySets, it's assumed we have many thousands of results, but we don't want to fetch all of them at once before returning to caller.
Database (and Django) does a query, then gives us a few items. Once that batch is done, QuerySet will ask the database for another batch of results.
This means that for both iterators and query sets, we can do a little work, then process a batch, without waiting for the entire list of results.
>>> p=SourceLine.objects.filter(project='redis')
>>> str(p.query)
'SELECT "app_sourceline"."id", ... FROM "app_sourceline"
WHERE "app_sourceline"."project" = redis'
>>> p.exists()
True
>>> str(p.exists().query)
AttributeError: 'bool' object has no attribute 'query'
>>> p=SourceLine.objects.filter(project='redis').exists()
123
>>> from django.db import connection ; connection.queries[-1]
u'QUERY = u\'SELECT (1) AS "a" FROM "app_sourceline"
WHERE "app_sourceline"."project" = %s LIMIT 1\'
- PARAMS = (u\'redis',)'
iterator/generator = "stream"
FP: functions operate on streams of immutable objects
QuerySet is a stream
Note
programming with composition
Elie Ceberio @eceberiotalener
Marcel Chastain @MarcelChastain @LADjango
Goz Inyama @notwitter
Can Your Programming Language Do This? by Joel Spolsky
http://www.joelonsoftware.com/items/2006/08/01.html
Wikipedia: Functional Programming
http://en.wikipedia.org/wiki/Functional_programming
Functional Programming HOWTO by Andy Kuchling
https://docs.python.org/2/howto/functional.html
Using Django querysets effectively by Dave Hall
(best blog title ever)
